The Model¶
The model is a gigantic mash up of three models, YoloV3, MiDAS and PlaneRCNN. YoloV3 detects the bounding boxes, MiDAS generates the depth map and PlaneRCNN detects the plane surfaces. The model turns out to be a model with a single head, and three tails (or a three-tailed fox/kitsune), each of which corresponds to the output of YoloV3, MiDAS and PlaneRCNN.
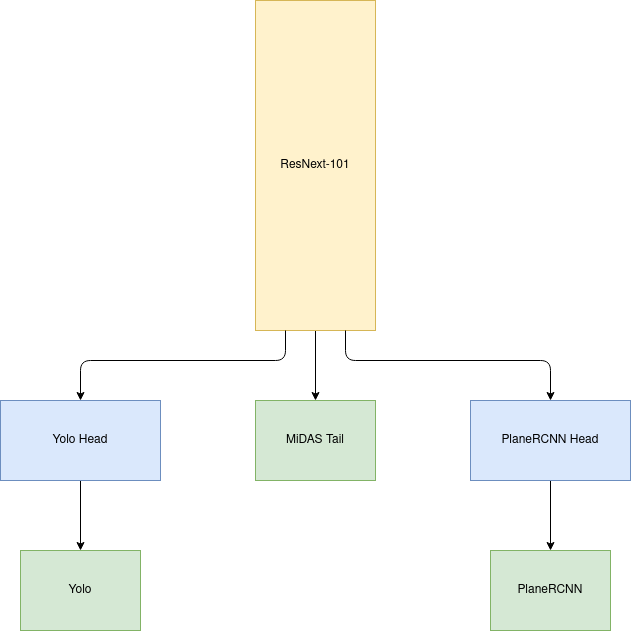
Model overview¶
MiDAS¶
MiDAS was taken as the backbone network because it uses ResNext101 as the feature extractor, and the outputs of the various stages of ResNext101 could be easily plugged in to the appropriate locations in YoloV3 and PlaneRCNN. The other alternatives was using the feature extractor of YoloV3 (DarkNet) or PlaneRCNN (ResNet), but the code bases were messy, and time could not be spared understanding it.
MiDAS was also used as is, with the pretrained weights and all the layers were frozen. The forward function of MiDAS was edited so that it returned the outputs of the various stages of the feature extractor (ResNext101).
YoloV3¶
To merge the YoloV3 model, the original YoloV3 model had to be chopped off at the correct position, and the tail section of the model had to be added to the main model.
To figure out where to chop the model off, the YoloV3 code had to be studied, and a relation between the pytorch layers and the layer in the YoloV3 config file had to be figured out (which took quite a while, YoloV3 code was messy). The updated YoloV3 config file was used to generated the chopped off model. The following image shows where the model was chopped off.
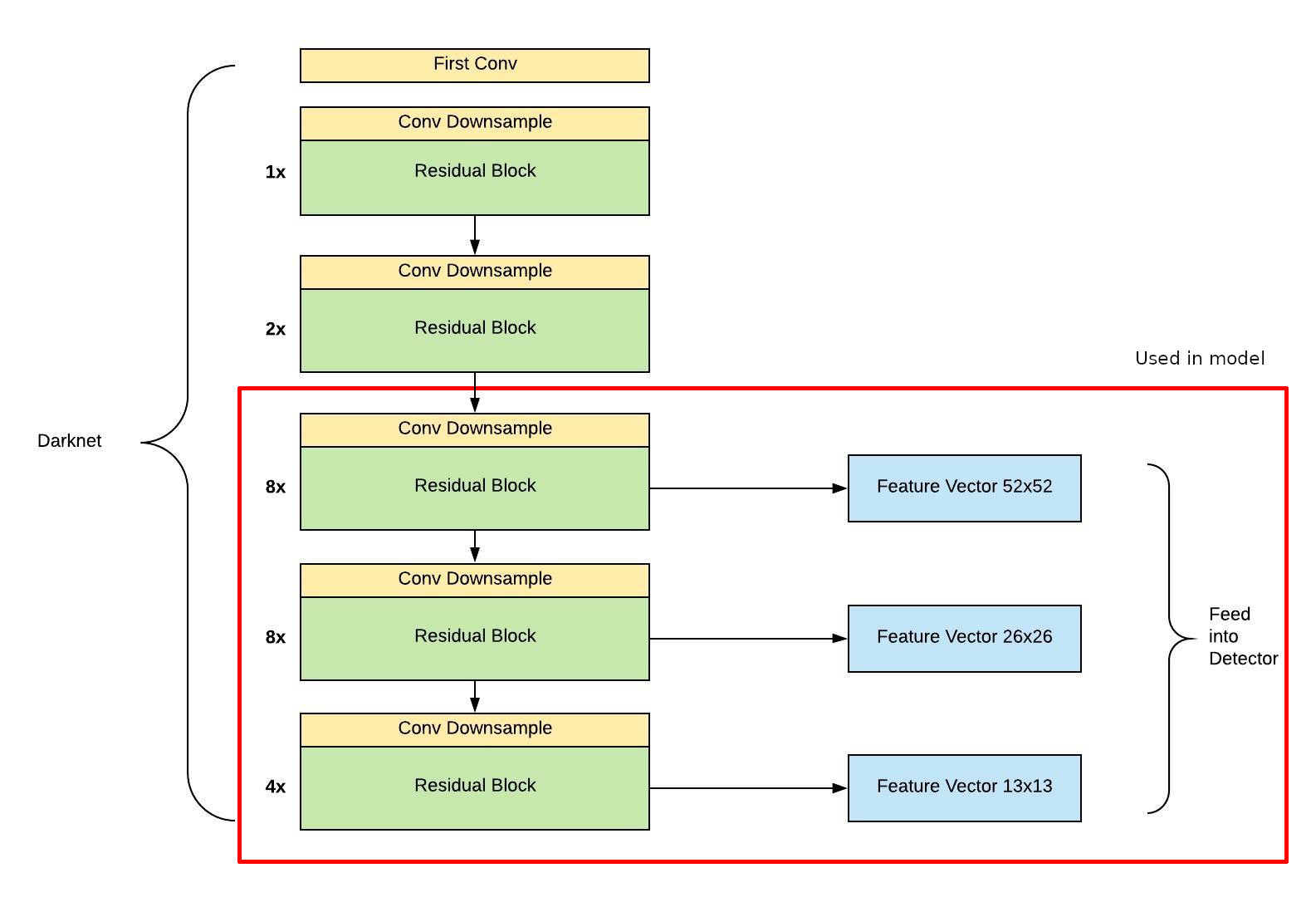
YoloV3 model overview¶
Bit of the YoloV3 model creation code was edited, to allow a skip connection between the inputs to the model and a layer in the later stages of the model.
Since the feature extractor used in MiDAS was ResNext101 and the feature extractor used in YoloV3 was DarkNet, additional layers had to be added between the outputs of ResNext101 and the input to the chopped off YoloV3, to let the network learn the required mapping that are needed due to the difference in extractor architectures. This “YoloHead”, had an architecture similar to squeeze and expand.

Yolo head¶
PlaneRCNN¶
Looking at the model code for PlaneRCNN, the layers of the feature extractor that PlaneRCNN used were given to the Feature Pyramid Network (FPN). luckily, the shapes of the outputs of those layers were same as the shapes of the outputs of the feature extractor in MiDAS, the ResNext101. To plug the MiDAS feature extractor outputs to FPN, a new FPN class was created which was the exact same as the original, with the difference being that the feature extractor outputs were given in the forward function instead in the constructor. The remainder of the model was left unchanged.
Similar to the extra “YoloHead”, couple of additional squeeze and expand layers were added in between the MiDAS extractor outputs and the PlaneRCNN network.
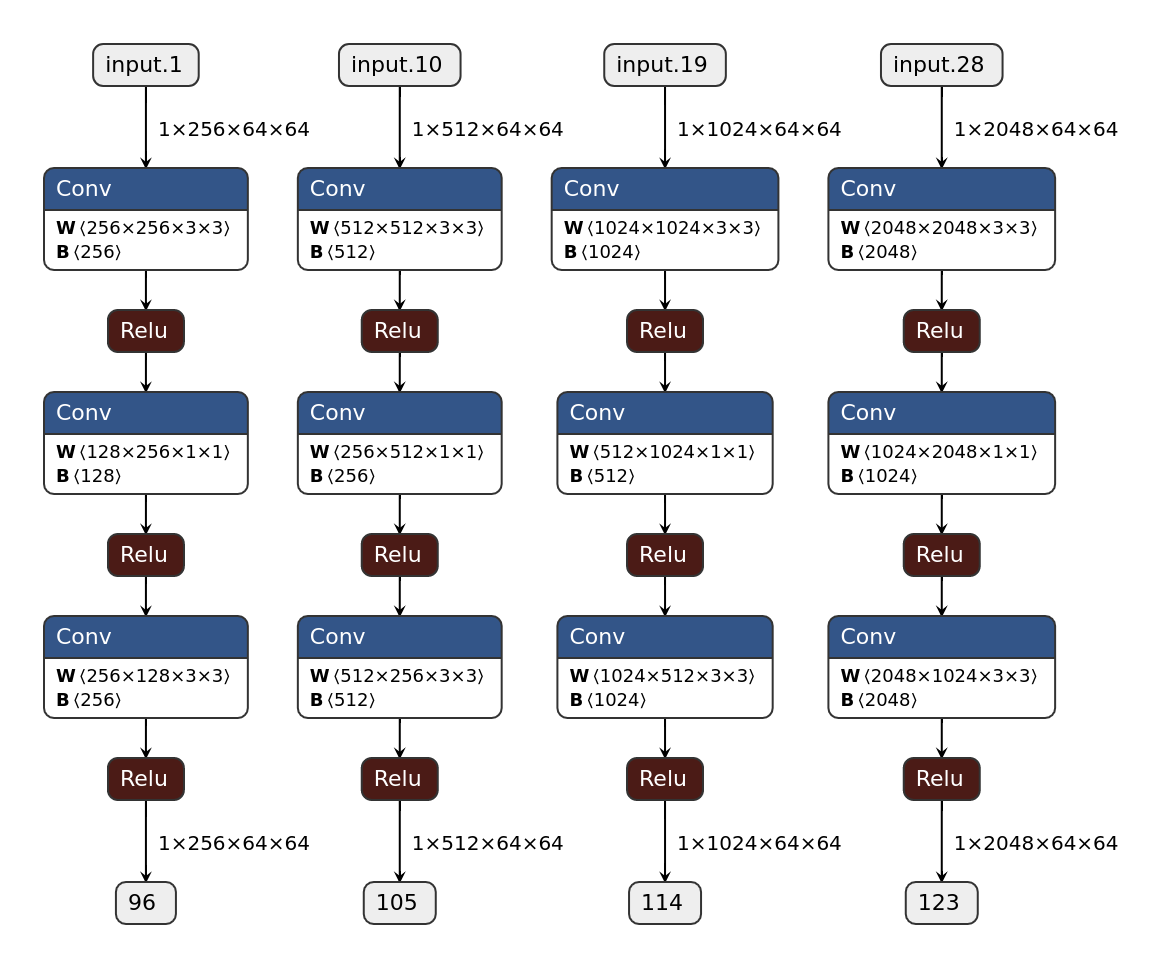
PlaneRCNN head¶